NFL Plays; Are they predictable and Does it matter?
To answer this question. I wanted to make a machine learning model that would predict whether an offensive play was either a Pass play or a Run play.
Data Collection
To do this, I used NFL play by play data that was obtained from the NFL Savant website.
The original data for the years of 2016–2019 was collected and had the shapes of the following:

What The Data Looked Like
The data from NFL savant comes in the present tense. What I mean by that is that all the features in a row had to do with the current play. For example, each row would detail the type of formation that the offensive team was in, the current down, and the distance needed to go for a first down. There were also features that had information about the type of play and the success of that play, such as the number of yards gained on the play and if the play resulted in points or a turnover. Each row would even state if there were any penalties during the play.
Choosing What Features To Use
Because I wanted to predict whether the next play would be a pass or a run, I would need to use many of the features from a previous play, (row on the dataset), to predict the type of play. I shifted these features up one row in the datasets.
I decided to limit the features to only those things that a person could possibly know before the snap of the football on the play that we were trying to predict.
To help with choosing the types of features that I would want to engineer to be used in the machine learning model, I tried to think about what type of information would help an offensive coordinator to choose the type of play he would run. I decided that things like the amount of time left in the game, the score, the down and the distance needed on the play, and the quality of the previous play would be some good starting features to help predict the play.
Using Only The Most Recent Play Information
I decided to limit my features to just information about the most recent play by the football team and not all the previous plays during the game, though it is likely that all the previous plays and their success influence whether the next play is a run or pass play.
I could have possibly engineered other features that contained information about the percentage of success in the previous run and pass plays, such as:

Again, this would likely have helped the model become more accurate. But I wanted to keep the features to the amount of information that a person watching the football game would have easy access to.
After doing wrangling and feature engineering of the data I ended up with data frames that had 32 columns.
Training Data And Test Data
For my training data, I used the data from the complete seasons of 2016, 2017, and 2018 years and also the beginning of the 2019 season up until the week of September 23, 2019.
The testing data included the week of September 23, 2019, to the end of the 2019 football season.

I further dropped some columns, such as the names of the teams, and ended up with the following features to use to begin to fit my models:

I split the training data into training and validation sets. I kept 75 percent as training data and 25 percent as validation data, giving me the following datasets:

Modeling
My baseline model was as follows:

The above image shows that if I were to guess a pass play each time, I would likely be right about 62 percent of the time.
First Model
In the pipeline for each of the following models, I used a onehotencoder to further expand the features ‘previous_offense_play’ and ‘Formation’.
The first model that I tried was a simple logistic regression. I was able to get an accuracy of 74.012%
Second Model
I then wanted to try some tree-based models. I first tried a Random Forrest Classifier and was able to get an accuracy of 74.119%.
Feature Importance
I used the Random Forrest to look at feature importances. I also use the library eli5 to use the permuter to look at the feature importances and came up with the following:

I decided to keep those features that were at least above zero.
XgBoost model
I then tried to fit an xgboost classifier model. I fit the model once using early stop and another time just choosing the parameters which were: ‘learning_rate’: 0.01, ‘max_depth’: 7, ‘n_estimators’: 500. Both of these obtained about a 82.69 in the “Area under the curve” score.
The following confusion matrix was produced from the xgboost classifier:
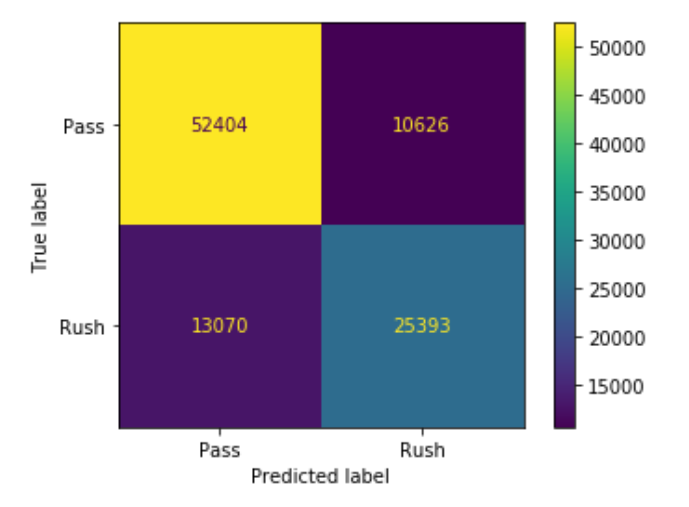
The precision for Pass plays was .80, while the precision for the Run plays was .70. The recall for Pass plays was .83 and the for Run plays was .95. The precision was likely higher for Pass plays because about 62% of the all the plays were Pass plays. Possibly for the same reason, the recall was better for the Run plays, simply because there were less of them present in the training data.
Which Teams Are The Most Predictable
After training and validating the xgboost model, I was curious to see the accuracy and the Area under the Curve for each NFL team. I separated the test dataset by each of the teams. I then used the xgboost model to predict on each team separately and got the following information.
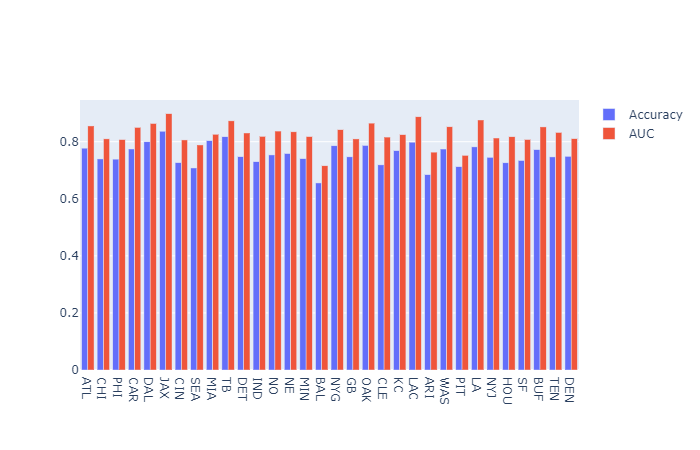
The accuracy and the AUC score for the test set as a whole was .7429 and .817 respectively.
It is interesting to note that the team that had the most wins during the regular season was the Baltimore Ravens at 14 wins. They also were the team that was the least predictable for the data from the test set which was from most of the 2019 season. The most predictable team, the Jacksonville Jaguars won only 6 games during the 2019 season. The Kansas City Chiefs won 12 regular-season games and were somewhere in the middle of the pack with respect to predictability. So being predictable probably does play somewhat of a factor in the success of a team, but not entirely. Sometimes being just plain talented helps.
Shap Values
The following are two force plots of the shap values, the first one when a Pass did occur and a Pass was predicted. The second one when a Run play did occur and the model predicted it as a run play.


On the Pass play, it can be seen that the model did use those things that we would also use instinctively to guess that it would likely be a Pass play, such as it being 3rd down with 12 yards to go, and down by 14 points.
The same could be said for the Run play, some of the larger factors in why it was predicting a Run are things that we would think are good reasons to guess a Run play.
Under Center Formation
It is interesting to note that the model used the formation “Under Center”, for both a reason that each play would be a Pass play and a Run play respectively. On the Run play the formation “Under Center” equals 1 which means that the offensive team was under center. On the Pass play, “Under Center” equals 0 which means that the offensive team was in a formation other than “Under Center”.
GitHub and Heroku
To look at more of the work that I have done, take a look at my notebook. Or if you would like, you can use the xgboost model on the heroku here to predict if a play is a pass or a run.
